Taking everything that you’ve learned in training a neural network based on NLP, we thought it might be a bit of fun to turn the tables away from classification and use your knowledge for prediction. Given a body of words, you could conceivably predict the word most likely to follow a given word or phrase, and once you’ve done that, to do it again, and again. With that in mind, this week you’ll build a poetry generator. It’s trained with the lyrics from traditional Irish songs, and can be used to produce beautiful-sounding verse of it’s own!
Long short-term memory (LSTM) is a type of recurrent neural network (RNN)
Code
import tensorflow as tfimport numpy as np from tensorflow.keras.layers import Embedding, LSTM, Dense, Bidirectionalfrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.preprocessing.text import Tokenizerfrom tensorflow.keras.preprocessing.sequence import pad_sequences
1 input data
Code
# Define the lyrics of the songdata="In the town of Athy one Jeremy Lanigan \n Battered away til he hadnt a pound. \nHis father died and made him a man again \n Left him a farm and ten acres of ground. \nHe gave a grand party for friends and relations \nWho didnt forget him when come to the wall, \nAnd if youll but listen Ill make your eyes glisten \nOf the rows and the ructions of Lanigans Ball. \nMyself to be sure got free invitation, \nFor all the nice girls and boys I might ask, \nAnd just in a minute both friends and relations \nWere dancing round merry as bees round a cask. \nJudy ODaly, that nice little milliner, \nShe tipped me a wink for to give her a call, \nAnd I soon arrived with Peggy McGilligan \nJust in time for Lanigans Ball. \nThere were lashings of punch and wine for the ladies, \nPotatoes and cakes; there was bacon and tea, \nThere were the Nolans, Dolans, OGradys \nCourting the girls and dancing away. \nSongs they went round as plenty as water, \nThe harp that once sounded in Taras old hall,\nSweet Nelly Gray and The Rat Catchers Daughter,\nAll singing together at Lanigans Ball. \nThey were doing all kinds of nonsensical polkas \nAll round the room in a whirligig. \nJulia and I, we banished their nonsense \nAnd tipped them the twist of a reel and a jig. \nAch mavrone, how the girls got all mad at me \nDanced til youd think the ceiling would fall. \nFor I spent three weeks at Brooks Academy \nLearning new steps for Lanigans Ball. \nThree long weeks I spent up in Dublin, \nThree long weeks to learn nothing at all,\n Three long weeks I spent up in Dublin, \nLearning new steps for Lanigans Ball. \nShe stepped out and I stepped in again, \nI stepped out and she stepped in again, \nShe stepped out and I stepped in again, \nLearning new steps for Lanigans Ball. \nBoys were all merry and the girls they were hearty \nAnd danced all around in couples and groups, \nTil an accident happened, young Terrance McCarthy \nPut his right leg through miss Finnertys hoops. \nPoor creature fainted and cried Meelia murther, \nCalled for her brothers and gathered them all. \nCarmody swore that hed go no further \nTil he had satisfaction at Lanigans Ball. \nIn the midst of the row miss Kerrigan fainted, \nHer cheeks at the same time as red as a rose. \nSome of the lads declared she was painted, \nShe took a small drop too much, I suppose. \nHer sweetheart, Ned Morgan, so powerful and able, \nWhen he saw his fair colleen stretched out by the wall, \nTore the left leg from under the table \nAnd smashed all the Chaneys at Lanigans Ball. \nBoys, oh boys, twas then there were runctions. \nMyself got a lick from big Phelim McHugh. \nI soon replied to his introduction \nAnd kicked up a terrible hullabaloo. \nOld Casey, the piper, was near being strangled. \nThey squeezed up his pipes, bellows, chanters and all. \nThe girls, in their ribbons, they got all entangled \nAnd that put an end to Lanigans Ball."# Split the long string per line and put in a listcorpus = data.lower().split("\n")
only have total 64 lines of words
Code
len(corpus)
64
Code
# Preview the resultprint(corpus)
['in the town of athy one jeremy lanigan ', ' battered away til he hadnt a pound. ', 'his father died and made him a man again ', ' left him a farm and ten acres of ground. ', 'he gave a grand party for friends and relations ', 'who didnt forget him when come to the wall, ', 'and if youll but listen ill make your eyes glisten ', 'of the rows and the ructions of lanigans ball. ', 'myself to be sure got free invitation, ', 'for all the nice girls and boys i might ask, ', 'and just in a minute both friends and relations ', 'were dancing round merry as bees round a cask. ', 'judy odaly, that nice little milliner, ', 'she tipped me a wink for to give her a call, ', 'and i soon arrived with peggy mcgilligan ', 'just in time for lanigans ball. ', 'there were lashings of punch and wine for the ladies, ', 'potatoes and cakes; there was bacon and tea, ', 'there were the nolans, dolans, ogradys ', 'courting the girls and dancing away. ', 'songs they went round as plenty as water, ', 'the harp that once sounded in taras old hall,', 'sweet nelly gray and the rat catchers daughter,', 'all singing together at lanigans ball. ', 'they were doing all kinds of nonsensical polkas ', 'all round the room in a whirligig. ', 'julia and i, we banished their nonsense ', 'and tipped them the twist of a reel and a jig. ', 'ach mavrone, how the girls got all mad at me ', 'danced til youd think the ceiling would fall. ', 'for i spent three weeks at brooks academy ', 'learning new steps for lanigans ball. ', 'three long weeks i spent up in dublin, ', 'three long weeks to learn nothing at all,', ' three long weeks i spent up in dublin, ', 'learning new steps for lanigans ball. ', 'she stepped out and i stepped in again, ', 'i stepped out and she stepped in again, ', 'she stepped out and i stepped in again, ', 'learning new steps for lanigans ball. ', 'boys were all merry and the girls they were hearty ', 'and danced all around in couples and groups, ', 'til an accident happened, young terrance mccarthy ', 'put his right leg through miss finnertys hoops. ', 'poor creature fainted and cried meelia murther, ', 'called for her brothers and gathered them all. ', 'carmody swore that hed go no further ', 'til he had satisfaction at lanigans ball. ', 'in the midst of the row miss kerrigan fainted, ', 'her cheeks at the same time as red as a rose. ', 'some of the lads declared she was painted, ', 'she took a small drop too much, i suppose. ', 'her sweetheart, ned morgan, so powerful and able, ', 'when he saw his fair colleen stretched out by the wall, ', 'tore the left leg from under the table ', 'and smashed all the chaneys at lanigans ball. ', 'boys, oh boys, twas then there were runctions. ', 'myself got a lick from big phelim mchugh. ', 'i soon replied to his introduction ', 'and kicked up a terrible hullabaloo. ', 'old casey, the piper, was near being strangled. ', 'they squeezed up his pipes, bellows, chanters and all. ', 'the girls, in their ribbons, they got all entangled ', 'and that put an end to lanigans ball.']
Code
# Initialize the Tokenizer classtokenizer = Tokenizer()# Generate the word index dictionarytokenizer.fit_on_texts(corpus)# Define the total words. You add 1 for the index `0` which is just the padding token.total_words =len(tokenizer.word_index) +1#print(f'word index dictionary: {tokenizer.word_index}')
only have total 263 unique words
Code
print(f'total words: {total_words}')
total words: 263
2 Preprocessing the Dataset
Next, you will be generating the training sequences and their labels. As discussed in the lectures, you will take each line of the song and generate inputs and labels from it. For example, if you only have one sentence: “I am using Tensorflow”, you want the model to learn the next word given any subphrase of this sentence:
2.1 INPUT LABEL
I —> am I am —> using I am using —> Tensorflow
Code
# Initialize the sequences listinput_sequences = []# Loop over every linefor line in corpus:# Tokenize the current line token_list = tokenizer.texts_to_sequences([line])[0]# Loop over the line several times to generate the subphrasesfor i inrange(1, len(token_list)):# Generate the subphrase n_gram_sequence = token_list[:i+1]# Append the subphrase to the sequences list input_sequences.append(n_gram_sequence)# Get the length of the longest linemax_sequence_len =max([len(x) for x in input_sequences])max_sequence_len
11
Code
# Pad all sequencesinput_sequences = np.array(pad_sequences(input_sequences, maxlen=max_sequence_len, padding='pre'))# Create inputs and label by splitting the last token in the subphrasesxs, labels = input_sequences[:,:-1],input_sequences[:,-1]# Convert the label into one-hot arraysys = tf.keras.utils.to_categorical(labels, num_classes=total_words)
first sentence
Code
# Get sample sentencesentence = corpus[0].split()print(f'sample sentence: {sentence}')
# Initialize token listtoken_list = []# Look up the indices of each word and append to the listfor word in sentence: token_list.append(tokenizer.word_index[word])
# Pick elementelem_number =6# Print token list and phraseprint(f'token list: {xs[elem_number]}')print(f'decoded to text: {tokenizer.sequences_to_texts([xs[elem_number]])}')
token list: [ 0 0 0 4 2 66 8 67 68 69]
decoded to text: ['in the town of athy one jeremy']
Code
# Print labelprint(f'one-hot label: {ys[elem_number]}')print(f'index of label: {np.argmax(ys[elem_number])}')
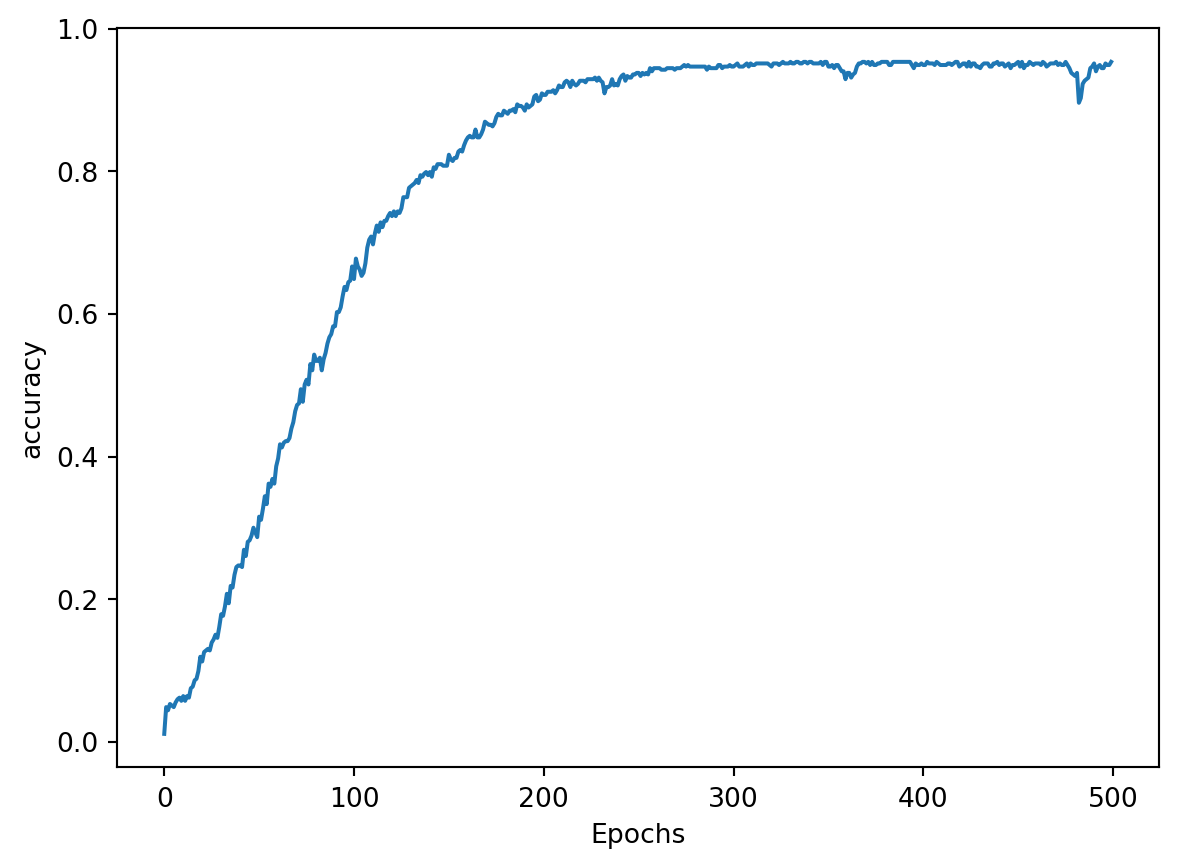
# Use categorical crossentropy because this is a multi-class problemmodel.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])# Print the model summarymodel.summary()
# Define seed textseed_text ="Laurence went to Dublin"# Define total words to predictnext_words =100# Loop until desired length is reachedfor _ inrange(next_words):# Convert the seed text to a token sequence token_list = tokenizer.texts_to_sequences([seed_text])[0]# Pad the sequence token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding='pre')# Feed to the model and get the probabilities for each index probabilities = model.predict(token_list)# Get the index with the highest probability predicted = np.argmax(probabilities, axis=-1)[0]# Ignore if index is 0 because that is just the padding.if predicted !=0:# Look up the word associated with the index. output_word = tokenizer.index_word[predicted]# Combine with the seed text seed_text +=" "+ output_word
Code
# Print the result print(seed_text)
Laurence went to Dublin harp stepped out and all all relations relations jig eyes suppose suppose glisten eyes midst brothers stepped stepped stepped in again again again again again again again suppose eyes away soon jig eyes glisten glisten pipes relations a rose eyes glisten suppose mcgilligan glisten glisten eyes away stepped call stepped stepped stepped in again again again again again again again suppose eyes away soon jig eyes glisten glisten pipes relations a rose eyes glisten suppose mcgilligan glisten glisten eyes away stepped call stepped stepped stepped in again again again again again again again suppose eyes away soon jig eyes glisten
6 Generating next 100 Text and random choose from top 3 probabilities words
Code
# Define seed textseed_text ="Laurence went to Dublin"# Define total words to predictnext_words =100# Loop until desired length is reachedfor _ inrange(next_words):# Convert the seed text to a token sequence token_list = tokenizer.texts_to_sequences([seed_text])[0]# Pad the sequence token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding='pre')# Feed to the model and get the probabilities for each index probabilities = model.predict(token_list)# Pick a random number from [1,2,3] choice = np.random.choice([1,2,3])# Sort the probabilities in ascending order # and get the random choice from the end of the array predicted = np.argsort(probabilities)[0][-choice]# Ignore if index is 0 because that is just the padding.if predicted !=0:# Look up the word associated with the index. output_word = tokenizer.index_word[predicted]# Combine with the seed text seed_text +=" "+ output_word
Code
# Print the result print(seed_text)
Laurence went to Dublin girls and round couples and groups relations relations make jig eyes glisten glisten listen listen glisten cask glisten one drop cask glisten cask cask man stepped in again relations we jig rose jig jig eyes might hall glisten call man again they saw jig stepped in and again again we ask call jig eyes suppose might glisten jig eyes suppose glisten man again i again relations ground glisten glisten glisten eyes away stepped up we call rose catchers catchers call daughter catchers eyes eyes suppose town suppose town midst mavrone brothers squeezed steps for lanigans friends in dublin dublin relations
7 using a bigger dataset
8 input data
Code
data=open('Laurences_generated_poetry.txt').read()# Split the long string per line and put in a listcorpus = data.lower().split("\n")
have total 1692 lines of words
Code
len(corpus)
1692
Code
# Preview the result#print(corpus)
Code
# Initialize the Tokenizer classtokenizer = Tokenizer()# Generate the word index dictionarytokenizer.fit_on_texts(corpus)# Define the total words. You add 1 for the index `0` which is just the padding token.total_words =len(tokenizer.word_index) +1#print(f'word index dictionary: {tokenizer.word_index}')
have total 2690 unique words
Code
print(f'total words: {total_words}')
total words: 2690
9 Preprocessing the Dataset
Next, you will be generating the training sequences and their labels. As discussed in the lectures, you will take each line of the song and generate inputs and labels from it. For example, if you only have one sentence: “I am using Tensorflow”, you want the model to learn the next word given any subphrase of this sentence:
9.1 INPUT LABEL
I —> am I am —> using I am using —> Tensorflow
Code
# Initialize the sequences listinput_sequences = []# Loop over every linefor line in corpus:# Tokenize the current line token_list = tokenizer.texts_to_sequences([line])[0]# Loop over the line several times to generate the subphrasesfor i inrange(1, len(token_list)):# Generate the subphrase n_gram_sequence = token_list[:i+1]# Append the subphrase to the sequences list input_sequences.append(n_gram_sequence)
Code
max_sequence_len =max([len(x) for x in input_sequences])max_sequence_len
16
Code
# Pad all sequencesinput_sequences = np.array(pad_sequences(input_sequences, maxlen=max_sequence_len, padding='pre'))# Create inputs and label by splitting the last token in the subphrasesxs, labels = input_sequences[:,:-1],input_sequences[:,-1]# Convert the label into one-hot arraysys = tf.keras.utils.to_categorical(labels, num_classes=total_words)
first sentence
Code
# Get sample sentencesentence = corpus[0].split()print(f'sample sentence: {sentence}')
# Initialize token listtoken_list = []# Look up the indices of each word and append to the listfor word in sentence: token_list.append(tokenizer.word_index[word])
Code
# Print the token listprint(token_list)
[51, 12, 96, 1217, 48, 2, 69]
Code
print(xs[5])
[ 0 0 0 0 0 0 0 0 0 51 12 96 1217 48
2]
Code
print(ys[5])
[0. 0. 0. ... 0. 0. 0.]
Code
# Pick elementelem_number =6# Print token list and phraseprint(f'token list: {xs[elem_number]}')print(f'decoded to text: {tokenizer.sequences_to_texts([xs[elem_number]])}')
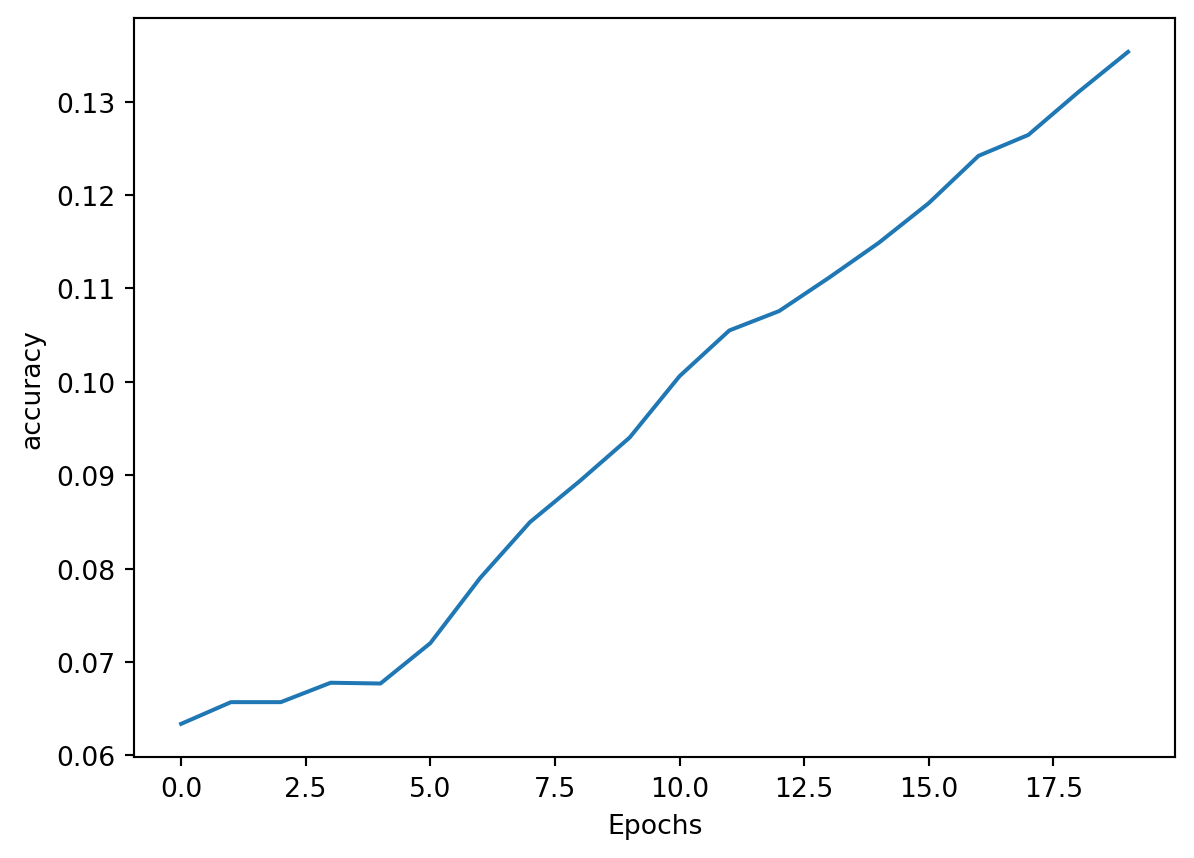
# Use categorical crossentropy because this is a multi-class problemmodel.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])# Print the model summarymodel.summary()
# Define seed textseed_text ="Laurence went to Dublin"# Define total words to predictnext_words =100# Loop until desired length is reachedfor _ inrange(next_words):# Convert the seed text to a token sequence token_list = tokenizer.texts_to_sequences([seed_text])[0]# Pad the sequence token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding='pre')# Feed to the model and get the probabilities for each index probabilities = model.predict(token_list)# Get the index with the highest probability predicted = np.argmax(probabilities, axis=-1)[0]# Ignore if index is 0 because that is just the padding.if predicted !=0:# Look up the word associated with the index. output_word = tokenizer.index_word[predicted]# Combine with the seed text seed_text +=" "+ output_word
Code
# Print the result print(seed_text)
Laurence went to Dublin and the loo casey the casey the loo hill of toome today to toome today to the fulfill today to toome today today today today today to toome today to toome today vermin fulfill fulfill whilst whilst whilst pound fulfill fulfill fulfill whilst toome fulfill fulfill today to toome today to fulfill today whilst whilst whilst whilst band whilst whilst toome fulfill fulfill whilst today to toome today to fulfill today fulfill fulfill fulfill whilst whilst today whilst fulfill fulfill fulfill whilst today to toome today to toome today to fulfill today to fulfill fulfill fulfill fulfill fulfill fulfill whilst
13 Generating next 100 Text and random choose from top 3 probabilities words
Code
# Define seed textseed_text ="Laurence went to Dublin"# Define total words to predictnext_words =100# Loop until desired length is reachedfor _ inrange(next_words):# Convert the seed text to a token sequence token_list = tokenizer.texts_to_sequences([seed_text])[0]# Pad the sequence token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding='pre')# Feed to the model and get the probabilities for each index probabilities = model.predict(token_list)# Pick a random number from [1,2,3] choice = np.random.choice([1,2,3])# Sort the probabilities in ascending order # and get the random choice from the end of the array predicted = np.argsort(probabilities)[0][-choice]# Ignore if index is 0 because that is just the padding.if predicted !=0:# Look up the word associated with the index. output_word = tokenizer.index_word[predicted]# Combine with the seed text seed_text +=" "+ output_word
Code
# Print the result print(seed_text)
Laurence went to Dublin of a band for a hill of the trace side to toome today to the whilst of fulfill by your laughtcr grandmother today to fulfill by my heart and me today of me bragh the fulfill of the toome today today to fulfill by to laughing by me in the morning and me laughing today of toome and fulfill by me laughing today to me heartfrom to toome fulfill whilst laughing whilst me laughing by the morning laughing by the ra ra casey the band of toome and fulfill today of toome and the fulfill of me today of the
---title: "W4:Sequence models and literature"execute: warning: false error: falseformat: html: toc: true toc-location: right code-fold: show code-tools: true number-sections: true code-block-bg: true code-block-border-left: "#31BAE9"---Week4 Sequence models and literatureTaking everything that you've learned in training a neural network based on NLP, we thought it might be a bit of fun to turn the tables away from classification and use your knowledge for prediction. Given a body of words, you could conceivably predict the word most likely to follow a given word or phrase, and once you've done that, to do it again, and again. With that in mind, this week you'll build a poetry generator. It's trained with the lyrics from traditional Irish songs, and can be used to produce beautiful-sounding verse of it's own!Long short-term memory (LSTM) is a type of recurrent neural network (RNN)```{python}import tensorflow as tfimport numpy as np from tensorflow.keras.layers import Embedding, LSTM, Dense, Bidirectionalfrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.preprocessing.text import Tokenizerfrom tensorflow.keras.preprocessing.sequence import pad_sequences```# input data```{python}# Define the lyrics of the songdata="In the town of Athy one Jeremy Lanigan \n Battered away til he hadnt a pound. \nHis father died and made him a man again \n Left him a farm and ten acres of ground. \nHe gave a grand party for friends and relations \nWho didnt forget him when come to the wall, \nAnd if youll but listen Ill make your eyes glisten \nOf the rows and the ructions of Lanigans Ball. \nMyself to be sure got free invitation, \nFor all the nice girls and boys I might ask, \nAnd just in a minute both friends and relations \nWere dancing round merry as bees round a cask. \nJudy ODaly, that nice little milliner, \nShe tipped me a wink for to give her a call, \nAnd I soon arrived with Peggy McGilligan \nJust in time for Lanigans Ball. \nThere were lashings of punch and wine for the ladies, \nPotatoes and cakes; there was bacon and tea, \nThere were the Nolans, Dolans, OGradys \nCourting the girls and dancing away. \nSongs they went round as plenty as water, \nThe harp that once sounded in Taras old hall,\nSweet Nelly Gray and The Rat Catchers Daughter,\nAll singing together at Lanigans Ball. \nThey were doing all kinds of nonsensical polkas \nAll round the room in a whirligig. \nJulia and I, we banished their nonsense \nAnd tipped them the twist of a reel and a jig. \nAch mavrone, how the girls got all mad at me \nDanced til youd think the ceiling would fall. \nFor I spent three weeks at Brooks Academy \nLearning new steps for Lanigans Ball. \nThree long weeks I spent up in Dublin, \nThree long weeks to learn nothing at all,\n Three long weeks I spent up in Dublin, \nLearning new steps for Lanigans Ball. \nShe stepped out and I stepped in again, \nI stepped out and she stepped in again, \nShe stepped out and I stepped in again, \nLearning new steps for Lanigans Ball. \nBoys were all merry and the girls they were hearty \nAnd danced all around in couples and groups, \nTil an accident happened, young Terrance McCarthy \nPut his right leg through miss Finnertys hoops. \nPoor creature fainted and cried Meelia murther, \nCalled for her brothers and gathered them all. \nCarmody swore that hed go no further \nTil he had satisfaction at Lanigans Ball. \nIn the midst of the row miss Kerrigan fainted, \nHer cheeks at the same time as red as a rose. \nSome of the lads declared she was painted, \nShe took a small drop too much, I suppose. \nHer sweetheart, Ned Morgan, so powerful and able, \nWhen he saw his fair colleen stretched out by the wall, \nTore the left leg from under the table \nAnd smashed all the Chaneys at Lanigans Ball. \nBoys, oh boys, twas then there were runctions. \nMyself got a lick from big Phelim McHugh. \nI soon replied to his introduction \nAnd kicked up a terrible hullabaloo. \nOld Casey, the piper, was near being strangled. \nThey squeezed up his pipes, bellows, chanters and all. \nThe girls, in their ribbons, they got all entangled \nAnd that put an end to Lanigans Ball."# Split the long string per line and put in a listcorpus = data.lower().split("\n")```only have total 64 lines of words```{python}len(corpus)``````{python}# Preview the resultprint(corpus)``````{python}# Initialize the Tokenizer classtokenizer = Tokenizer()# Generate the word index dictionarytokenizer.fit_on_texts(corpus)# Define the total words. You add 1 for the index `0` which is just the padding token.total_words =len(tokenizer.word_index) +1#print(f'word index dictionary: {tokenizer.word_index}')```only have total 263 unique words```{python}print(f'total words: {total_words}')```# Preprocessing the DatasetNext, you will be generating the training sequences and their labels. As discussed in the lectures, you will take each line of the song and generate inputs and labels from it. For example, if you only have one sentence: "I am using Tensorflow", you want the model to learn the next word given any subphrase of this sentence:## INPUT LABELI ---\> am I am ---\> using I am using ---\> Tensorflow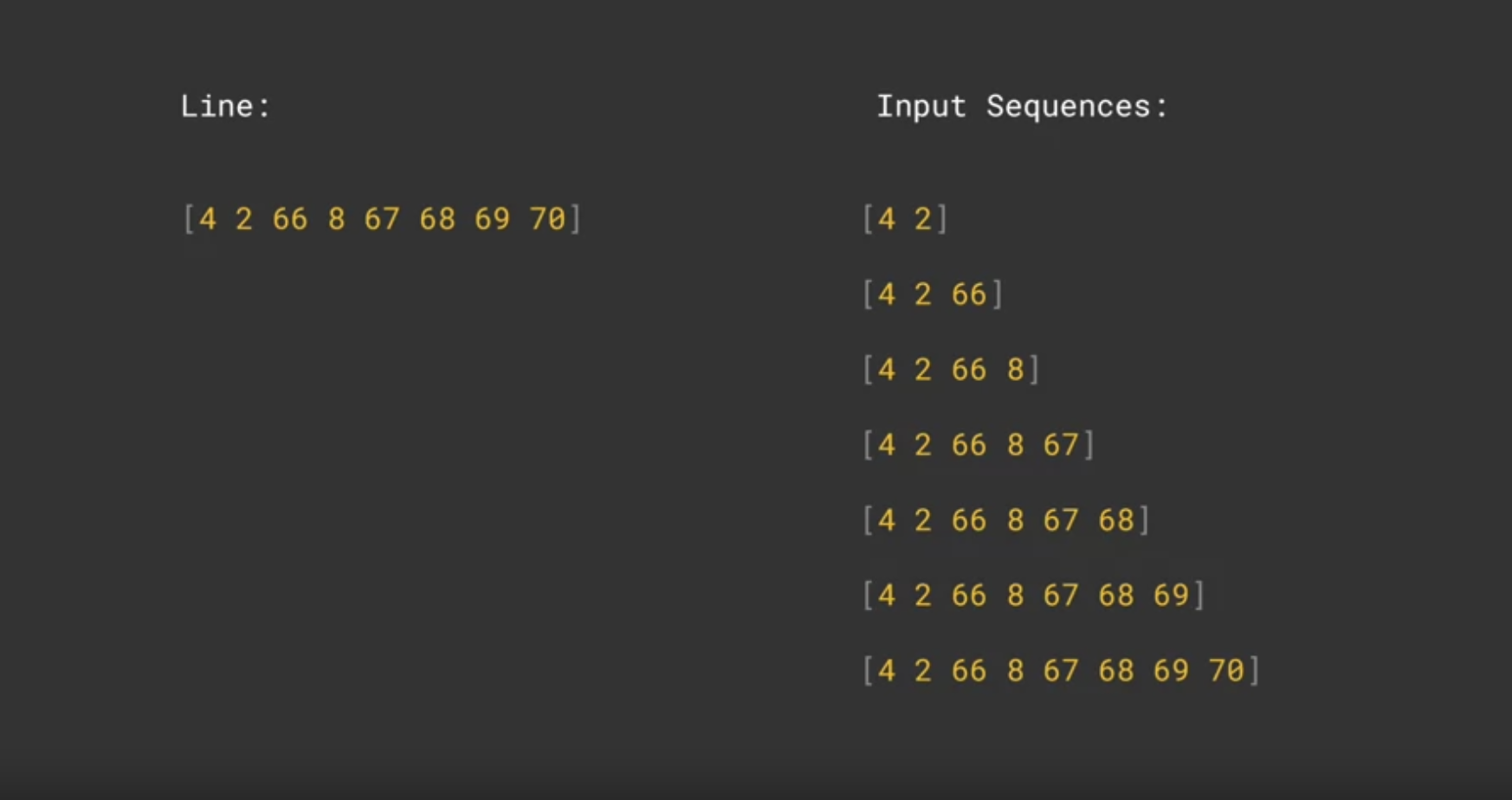```{python}# Initialize the sequences listinput_sequences = []# Loop over every linefor line in corpus:# Tokenize the current line token_list = tokenizer.texts_to_sequences([line])[0]# Loop over the line several times to generate the subphrasesfor i inrange(1, len(token_list)):# Generate the subphrase n_gram_sequence = token_list[:i+1]# Append the subphrase to the sequences list input_sequences.append(n_gram_sequence)# Get the length of the longest linemax_sequence_len =max([len(x) for x in input_sequences])max_sequence_len``````{python}# Pad all sequencesinput_sequences = np.array(pad_sequences(input_sequences, maxlen=max_sequence_len, padding='pre'))# Create inputs and label by splitting the last token in the subphrasesxs, labels = input_sequences[:,:-1],input_sequences[:,-1]# Convert the label into one-hot arraysys = tf.keras.utils.to_categorical(labels, num_classes=total_words)```first sentence```{python}# Get sample sentencesentence = corpus[0].split()print(f'sample sentence: {sentence}')```first sentence after tokenizer```{python}#| output: false# Initialize token listtoken_list = []# Look up the indices of each word and append to the listfor word in sentence: token_list.append(tokenizer.word_index[word])``````{python}# Print the token listprint(token_list)``````{python}print(xs[5])``````{python}print(ys[5])``````{python}# Pick elementelem_number =6# Print token list and phraseprint(f'token list: {xs[elem_number]}')print(f'decoded to text: {tokenizer.sequences_to_texts([xs[elem_number]])}')``````{python}# Print labelprint(f'one-hot label: {ys[elem_number]}')print(f'index of label: {np.argmax(ys[elem_number])}')``````{python}# Pick elementelem_number =5# Print token list and phraseprint(f'token list: {xs[elem_number]}')print(f'decoded to text: {tokenizer.sequences_to_texts([xs[elem_number]])}')# Print labelprint(f'one-hot label: {ys[elem_number]}')print(f'index of label: {np.argmax(ys[elem_number])}')```# Build the Model## define model```{python}# Build the modelmodel = Sequential([ Embedding(total_words, 64), Bidirectional(LSTM(20)), Dense(total_words, activation='softmax')])```## compile model```{python}# Use categorical crossentropy because this is a multi-class problemmodel.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])# Print the model summarymodel.summary()```## train model```{python}# Train the modelhistory = model.fit(xs, ys, epochs=500,verbose=0)```## model performance:```{python}import matplotlib.pyplot as plt# Plot utilitydef plot_graphs(history, string): plt.plot(history.history[string]) plt.xlabel("Epochs") plt.ylabel(string) plt.show()# Visualize the accuracyplot_graphs(history, 'accuracy')```# Generating next word```{python}seed_text ="Laurence went to Dublin"token_list = tokenizer.texts_to_sequences([seed_text])[0]token_list``````{python}token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding='pre')token_list``````{python}probabilities = model.predict(token_list)predicted = np.argmax(probabilities, axis=-1)[0]predicted``````{python}output_word = tokenizer.index_word[predicted]output_word```# Generating next 100 Text```{python}#| output: false# Define seed textseed_text ="Laurence went to Dublin"# Define total words to predictnext_words =100# Loop until desired length is reachedfor _ inrange(next_words):# Convert the seed text to a token sequence token_list = tokenizer.texts_to_sequences([seed_text])[0]# Pad the sequence token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding='pre')# Feed to the model and get the probabilities for each index probabilities = model.predict(token_list)# Get the index with the highest probability predicted = np.argmax(probabilities, axis=-1)[0]# Ignore if index is 0 because that is just the padding.if predicted !=0:# Look up the word associated with the index. output_word = tokenizer.index_word[predicted]# Combine with the seed text seed_text +=" "+ output_word``````{python}# Print the result print(seed_text)```# Generating next 100 Text and random choose from top 3 probabilities words```{python}#| output: false# Define seed textseed_text ="Laurence went to Dublin"# Define total words to predictnext_words =100# Loop until desired length is reachedfor _ inrange(next_words):# Convert the seed text to a token sequence token_list = tokenizer.texts_to_sequences([seed_text])[0]# Pad the sequence token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding='pre')# Feed to the model and get the probabilities for each index probabilities = model.predict(token_list)# Pick a random number from [1,2,3] choice = np.random.choice([1,2,3])# Sort the probabilities in ascending order # and get the random choice from the end of the array predicted = np.argsort(probabilities)[0][-choice]# Ignore if index is 0 because that is just the padding.if predicted !=0:# Look up the word associated with the index. output_word = tokenizer.index_word[predicted]# Combine with the seed text seed_text +=" "+ output_word``````{python}# Print the result print(seed_text)```# using a bigger dataset# input data```{python}data=open('Laurences_generated_poetry.txt').read()# Split the long string per line and put in a listcorpus = data.lower().split("\n")```have total 1692 lines of words```{python}len(corpus)``````{python}# Preview the result#print(corpus)``````{python}# Initialize the Tokenizer classtokenizer = Tokenizer()# Generate the word index dictionarytokenizer.fit_on_texts(corpus)# Define the total words. You add 1 for the index `0` which is just the padding token.total_words =len(tokenizer.word_index) +1#print(f'word index dictionary: {tokenizer.word_index}')```have total 2690 unique words```{python}print(f'total words: {total_words}')```# Preprocessing the DatasetNext, you will be generating the training sequences and their labels. As discussed in the lectures, you will take each line of the song and generate inputs and labels from it. For example, if you only have one sentence: "I am using Tensorflow", you want the model to learn the next word given any subphrase of this sentence:## INPUT LABELI ---\> am I am ---\> using I am using ---\> Tensorflow```{python}#| output: false# Initialize the sequences listinput_sequences = []# Loop over every linefor line in corpus:# Tokenize the current line token_list = tokenizer.texts_to_sequences([line])[0]# Loop over the line several times to generate the subphrasesfor i inrange(1, len(token_list)):# Generate the subphrase n_gram_sequence = token_list[:i+1]# Append the subphrase to the sequences list input_sequences.append(n_gram_sequence)``````{python}max_sequence_len =max([len(x) for x in input_sequences])max_sequence_len``````{python}# Pad all sequencesinput_sequences = np.array(pad_sequences(input_sequences, maxlen=max_sequence_len, padding='pre'))# Create inputs and label by splitting the last token in the subphrasesxs, labels = input_sequences[:,:-1],input_sequences[:,-1]# Convert the label into one-hot arraysys = tf.keras.utils.to_categorical(labels, num_classes=total_words)```first sentence```{python}# Get sample sentencesentence = corpus[0].split()print(f'sample sentence: {sentence}')```first sentence after tokenizer```{python}#| output: false# Initialize token listtoken_list = []# Look up the indices of each word and append to the listfor word in sentence: token_list.append(tokenizer.word_index[word])``````{python}# Print the token listprint(token_list)``````{python}print(xs[5])``````{python}print(ys[5])``````{python}# Pick elementelem_number =6# Print token list and phraseprint(f'token list: {xs[elem_number]}')print(f'decoded to text: {tokenizer.sequences_to_texts([xs[elem_number]])}')``````{python}# Print labelprint(f'one-hot label: {ys[elem_number]}')print(f'index of label: {np.argmax(ys[elem_number])}')``````{python}# Pick elementelem_number =5# Print token list and phraseprint(f'token list: {xs[elem_number]}')print(f'decoded to text: {tokenizer.sequences_to_texts([xs[elem_number]])}')# Print labelprint(f'one-hot label: {ys[elem_number]}')print(f'index of label: {np.argmax(ys[elem_number])}')```# Build the Model## define model```{python}# Build the modelmodel = Sequential([ Embedding(total_words, 64), Bidirectional(LSTM(20)), Dense(total_words, activation='softmax')])```## compile model```{python}# Use categorical crossentropy because this is a multi-class problemmodel.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])# Print the model summarymodel.summary()```## train model```{python}# Train the modelhistory = model.fit(xs, ys, epochs=20,verbose=0)```## model performance:```{python}import matplotlib.pyplot as plt# Plot utilitydef plot_graphs(history, string): plt.plot(history.history[string]) plt.xlabel("Epochs") plt.ylabel(string) plt.show()# Visualize the accuracyplot_graphs(history, 'accuracy')```# Generating next word```{python}seed_text ="Laurence went to Dublin"token_list = tokenizer.texts_to_sequences([seed_text])[0]token_list``````{python}token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding='pre')token_list``````{python}probabilities = model.predict(token_list)predicted = np.argmax(probabilities, axis=-1)[0]predicted``````{python}output_word = tokenizer.index_word[predicted]output_word```# Generating next 100 Text```{python}#| output: false# Define seed textseed_text ="Laurence went to Dublin"# Define total words to predictnext_words =100# Loop until desired length is reachedfor _ inrange(next_words):# Convert the seed text to a token sequence token_list = tokenizer.texts_to_sequences([seed_text])[0]# Pad the sequence token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding='pre')# Feed to the model and get the probabilities for each index probabilities = model.predict(token_list)# Get the index with the highest probability predicted = np.argmax(probabilities, axis=-1)[0]# Ignore if index is 0 because that is just the padding.if predicted !=0:# Look up the word associated with the index. output_word = tokenizer.index_word[predicted]# Combine with the seed text seed_text +=" "+ output_word``````{python}# Print the result print(seed_text)```# Generating next 100 Text and random choose from top 3 probabilities words```{python}#| output: false# Define seed textseed_text ="Laurence went to Dublin"# Define total words to predictnext_words =100# Loop until desired length is reachedfor _ inrange(next_words):# Convert the seed text to a token sequence token_list = tokenizer.texts_to_sequences([seed_text])[0]# Pad the sequence token_list = pad_sequences([token_list], maxlen=max_sequence_len-1, padding='pre')# Feed to the model and get the probabilities for each index probabilities = model.predict(token_list)# Pick a random number from [1,2,3] choice = np.random.choice([1,2,3])# Sort the probabilities in ascending order # and get the random choice from the end of the array predicted = np.argsort(probabilities)[0][-choice]# Ignore if index is 0 because that is just the padding.if predicted !=0:# Look up the word associated with the index. output_word = tokenizer.index_word[predicted]# Combine with the seed text seed_text +=" "+ output_word``````{python}# Print the result print(seed_text)```# resource:https://www.coursera.org/learn/natural-language-processing-tensorflowhttps://github.com/https-deeplearning-ai/tensorflow-1-public/tree/main/C3