Code
import os
os.system('pip install tensorflow_decision_forests')with house price data
import os
os.system('pip install tensorflow_decision_forests')import os
# Keep using Keras 2
os.environ['TF_USE_LEGACY_KERAS'] = '1'
import tensorflow_decision_forests as tfdf
import numpy as np
import pandas as pd
import tensorflow as tf
import tf_keras
import math# Check the version of TensorFlow Decision Forests
print("Found TensorFlow Decision Forests v" + tfdf.__version__)Found TensorFlow Decision Forests v1.9.0data download form kaggle
train_file_path = "data/train.csv"
dataset_df = pd.read_csv(train_file_path)
print("Full train dataset shape is {}".format(dataset_df.shape))Full train dataset shape is (1460, 81)dataset_df.head(3)| Id | MSSubClass | MSZoning | LotFrontage | LotArea | Street | Alley | LotShape | LandContour | Utilities | ... | PoolArea | PoolQC | Fence | MiscFeature | MiscVal | MoSold | YrSold | SaleType | SaleCondition | SalePrice | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 60 | RL | 65.0 | 8450 | Pave | NaN | Reg | Lvl | AllPub | ... | 0 | NaN | NaN | NaN | 0 | 2 | 2008 | WD | Normal | 208500 |
| 1 | 2 | 20 | RL | 80.0 | 9600 | Pave | NaN | Reg | Lvl | AllPub | ... | 0 | NaN | NaN | NaN | 0 | 5 | 2007 | WD | Normal | 181500 |
| 2 | 3 | 60 | RL | 68.0 | 11250 | Pave | NaN | IR1 | Lvl | AllPub | ... | 0 | NaN | NaN | NaN | 0 | 9 | 2008 | WD | Normal | 223500 |
3 rows × 81 columns
dataset_df = dataset_df.drop('Id', axis=1)
dataset_df.head(3)| MSSubClass | MSZoning | LotFrontage | LotArea | Street | Alley | LotShape | LandContour | Utilities | LotConfig | ... | PoolArea | PoolQC | Fence | MiscFeature | MiscVal | MoSold | YrSold | SaleType | SaleCondition | SalePrice | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 60 | RL | 65.0 | 8450 | Pave | NaN | Reg | Lvl | AllPub | Inside | ... | 0 | NaN | NaN | NaN | 0 | 2 | 2008 | WD | Normal | 208500 |
| 1 | 20 | RL | 80.0 | 9600 | Pave | NaN | Reg | Lvl | AllPub | FR2 | ... | 0 | NaN | NaN | NaN | 0 | 5 | 2007 | WD | Normal | 181500 |
| 2 | 60 | RL | 68.0 | 11250 | Pave | NaN | IR1 | Lvl | AllPub | Inside | ... | 0 | NaN | NaN | NaN | 0 | 9 | 2008 | WD | Normal | 223500 |
3 rows × 80 columns
#dataset_df.info()import numpy as np
def split_dataset(dataset, test_ratio=0.30):
test_indices = np.random.rand(len(dataset)) < test_ratio
return dataset[~test_indices], dataset[test_indices]
train_ds_pd, valid_ds_pd = split_dataset(dataset_df)
print("{} examples in training, {} examples in testing.".format(
len(train_ds_pd), len(valid_ds_pd)))1029 examples in training, 431 examples in testing.label = 'SalePrice'
train_ds = tfdf.keras.pd_dataframe_to_tf_dataset(train_ds_pd, label=label, task = tfdf.keras.Task.REGRESSION)
valid_ds = tfdf.keras.pd_dataframe_to_tf_dataset(valid_ds_pd, label=label, task = tfdf.keras.Task.REGRESSION)# Specify the model.
model_1 = tfdf.keras.RandomForestModel(task = tfdf.keras.Task.REGRESSION)Use /var/folders/v3/pzt9c47n1nbcsmybsg_w0lhw0000gn/T/tmptkal5dhv as temporary training directorymodel_1.compile(metrics=["mse"])model_1.fit(train_ds)Reading training dataset...
Training dataset read in 0:00:01.731521. Found 1029 examples.
Training model...
Model trained in 0:00:00.564812
Compiling model...
Model compiled.<tf_keras.src.callbacks.History at 0x2860a47d0>evaluation = model_1.evaluate(valid_ds, return_dict=True)
print()1/1 [==============================] - ETA: 0s - loss: 0.0000e+00 - mse: 786470720.00001/1 [==============================] - 2s 2s/step - loss: 0.0000e+00 - mse: 786470720.0000
for name, value in evaluation.items():
mse=valueRMSE
import math
math.sqrt(mse)28044.085294407447import matplotlib.pyplot as plt
logs = model_1.make_inspector().training_logs()
plt.plot([log.num_trees for log in logs], [log.evaluation.rmse for log in logs])
plt.xlabel("Number of trees")
plt.ylabel("RMSE (out-of-bag)")
plt.show()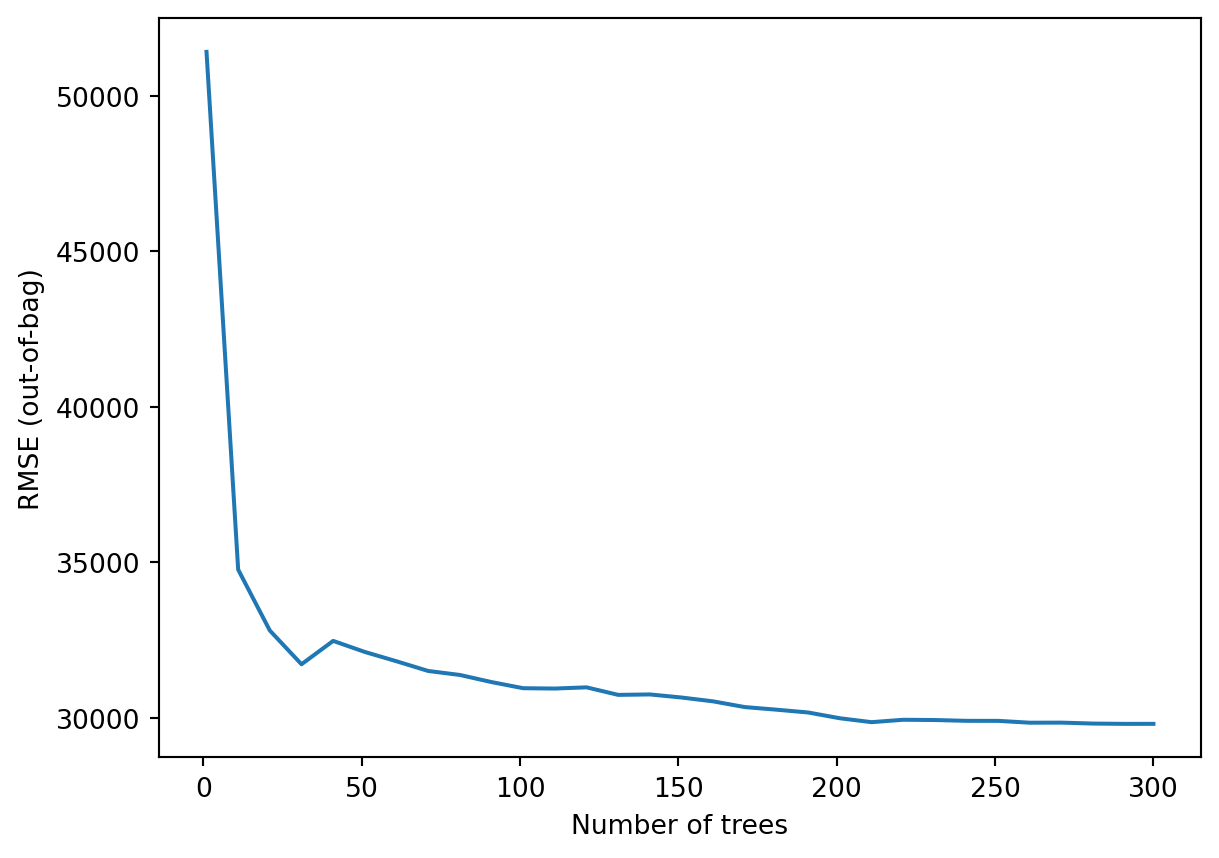
https://colab.research.google.com/github/tensorflow/decision-forests/blob/main/documentation/tutorials/beginner_colab.ipynb#scrollTo=xUy4ULEMtDXB